[database] トランザクション分離レベルのメモ
RDBMS/SQL の話のなかで、基礎的な知識として必ずでてくる(であろう) 4 種類のトランザクション分離レベル (transaction isolation levels) ですが、腑に落ちたことがなく気持ち悪い印象をもっていました。そこで、差異を正しく理解すべく、 Bernstein さん、 Jim Gray さんたちの論文を読んでみました。個人的に興味のある点は、 Phantom Read とは何か? と Snapshot Isolation はどの程度の隔離レベルか? という 2 点です。
PostgreSQL のトランザクション分離
PostgreSQL は read committed と serializable のトランザクション分離レベルを実装しています。
In PostgreSQL, you can request any of the four standard transaction isolation levels. But internally, there are only two distinct isolation levels, which correspond to the levels Read Committed and Serializable.
PostgreSQL: Documentation: Manuals: PostgreSQL 8.4: Transaction Isolation
しかしながら、 数学的な(= mathematical) serializable ではない、と記述されています。
13.2.2.1. Serializable Isolation versus True Serializability The intuitive meaning (and mathematical definition) of "serializable" execution is that any two successfully committed concurrent transactions will appear to have executed strictly serially, one after the other ― although which one appeared to occur first might not be predictable in advance. It is important to realize that forbidding the undesirable behaviors listed in Table 13-1 is not sufficient to guarantee true serializability, and in fact PostgreSQL's Serializable mode does not guarantee serializable execution in this sense. As an example, consider a table mytab, initially containing:
PostgreSQL: Documentation: Manuals: PostgreSQL 8.4: Transaction Isolation
論文「ANSI SQL 分離レベルの批評」
みつけたのが、この論文。ぼくはあまり歴史とか知りませんが、きっと古典的な論文っぽいかんじが漂っています。
authors:
Hal Berenson, Phil Bernstein, Jim Gray, Jim Melton, Elizabeth O'Neil, and Patrick O'Neilabstract:
ANSI SQL-92 [MS, ANSI] defines Isolation Levels in terms of phenomena: Dirty Reads, Non-Repeatable Reads, and Phantoms. This paper shows that these phenomena and the ANSI SQL definitions fail to characterize several popular isolation levels, including the standard locking implementations of the levels. Investigating the ambiguities of the phenomena leads to clearer definitions; in addition new phenomena that better characterize isolation types are introduced. An important multiversion isolation type, Snapshot Isolation, is defined.アブストラクト(訳):
A Critique of ANSI SQL Isolation Levels - Microsoft Research
ANSI SQL-92 では、現象、 Dirty Reads, Non-Repeatable Reads, そして Phantoms の観点から分離レベルを定義している。この論文では、これらの現象と ANSI SQL 定義がいくつかの良く使われている分離レベル、標準的なロックによるレベルの実装を特徴づけることに失敗していることを示す。曖昧さを調べることにより、より明確な定義を導き、また、分離タイプを特徴づける新しい現象を導入する。重要な、 multiversion 分離タイプである、 Snapshot 分離を定義する。
ANSI の分離レベル (section 2.2)
3 つの「現象」
によって定義される 4 つのレベル
- リードアンコミッティド
- リードコミッティド
- リピータブルリード
- シリアライザブル
ここだけ片仮名に変わるとコピペが見えみえですが、まぁここはまじめに書くつもりがないので、下のページにゆずります。よくみる表が載っています。
4つの分離レベルと3つの現象の関係は以下の通りです。
ThinkIT 第3回:トランザクションの比較 (1/4)
Locking (section 2.3)
ロックのための言葉を導入します。
- Read locks
- Shared
- Write locks
- Exclusive
- Read/Write predicate lock
-
について、それを満たす全てのデータに対するロック。未来のデータも含むので、無限集合のこともある。
さらに定義が続きます。
- well-fromed reads/writes
- reads/writes の*前*に、対象のデータ、または predicate のロックを要求する場合、 well-formed と言う。
- long duration
- あるトランザクションによって取得されたロックが、commits か aborts まで保持される場合、 long duration と言う。
- short duration
- long duration ではないもの。ex. ロック取得して更新操作後にすぐ開放されるロック。
これらのロックの種類の組み合わせでもって、 "Locking Isolation Levels" というものを定義します。 (Table. 2)
表のなかから、 ロック版 (in terms of locks) の READ UNCOMMITTED, READ COMMITTED, REPEATABLE READ について抜粋してみます。
- Degree 1 = Locking READ UNCOMMITTED
- Read Locks
- (none required)
- Write Locks
- Well-formed Writes
- Long duration Write locks
- Read Locks
- Degree 2 = Locking READ COMMITTED
- Read Locks
- Well-formed Reads
- Short duration Read Locks (both data-item and predicate)
- Write Locks
- Well-formed Writes
- Long duration Write locks
- Read Locks
- Locking REPEATABLE READ
- Read Locks
- Well-formed Reads
- Long duration data-item Read Locks
- Short duration Read Predicate Read Locks
- Write Locks
- Well-formed Writes
- Long duration Write locks
- Read Locks
- Degree 3 = Locking SERIALIZABLE
- Read Locks
- Well-formed Reads
- Long duration Read Locks (both data-item and predicate)
- Write Locks
- Well-formed Writes
- Long duration Write locks
- Read Locks
ゴチャゴチャして分かりにくいですが、 Write 側では、全てのレベルで、 well-formed かつ Long duration locks が入っています。つまり READ UNCOMMITTED であってもアトミックであるためには、書き込みにはそれらが必要ということですね。
それに対して、 Read 側がレベルを分けるようになっています。例えば、Locking REPEATABLE READ では、一度読んだデータに対して、 long duration locks を要求しています。スッと腑に落ちますね。
この後、分離レベルに半順序の定義をしています。
- stronger (<<) : L1 << L2 <=> L1 で許される non-serializable な履歴が L2 では禁止される、かつ、 L2 で許される non-serializable な履歴が L1 で許される
- equivalent (==) : 許される non-serializable な履歴の集合が一致する
- no stronger (<<= :論文では << の下に横棒) : << OR ==
- incomparable (>><<) : お互いに、相手では許されるが、自分では禁止される non-serializable な履歴が存在する
Analyzing ANSI SQL Levels (section 3)
ANSI の現象で定義したレベル (section 2.2) と ロックで定義したレベル (section 2.3) の関連付けを行っています。あまり面白みが無いので省略。
Cursor Stability (section 4.1)
Section 4 では "Other Isolation Types" として、いくつかの分離レベルを説明しています。
まずは section 4.1 から "Cursor Stability"。この分離レベルは「 lost update を防ぐように設計されている」と書かれています。現象 "lost update" の定義は次のとおりです。
P4: r1[x] ... w2[x] ... w1[x] ... c1 / Phenomena: Lost Update
これはトランザクションの履歴を表しています。(正確には「現象」を表していると書いてあり、その心は ... のところは任意のオペレーションが入るからだと思われます)。
凡例は以下のとおりです。
- r1[x]
- T1(トランザクション1) がデータ x を read
- w2[x]
- T2(トランザクション2) がデータ x を write
- r1[P]
- T1 が predicate P で read
- w1[P]
- T1 が predicate P で write
- c1
- T1 が commit
- a1
- T1 が abort
具体的な履歴として、ひとつ例が書いてあります。
H4: r1[x=100] r2[x=100] w2[x=120] c2 w1[x=130] c1
ここで、 w1[130] は r1[x=100] に対して、 x = x(=100) + 30 と更新した気持ちです。
Lost update を防ぐために、 Cursor Stability では、 READ COMMITTED のロックに加えて、新しい read action "FETCH" を導入します。ここで cursor からの FETCH は現在のデータアイテムにロックがあり、cursor が(通常は commit により)閉じられるまで続くことを要求します。カーソルから FETCH した後に、カーソルはそのままで x に更新を入れると、short duration の read lock をもった状態で write lock が取得されることになります。
そこで、2 つの操作を定義して、
- rc (read cursor)
- FETCH
- wc (write cursor)
- FETCH した *現在の* レコードに対する write
P4: rc1[x] ... w2[x] ... wc1[x] ... c1 / Phenomena: Lost Update
という現象を見ると、rc1 -> wc1 に挟まれた w2 はロックが取得できないことが分かります。具体的には、rc1[x] の read lock と衝突します。
このセクションの結論としては、以下の順序関係が書いてあります。
READ COMMITTED << Cursor Stability << REPEATABLE READ
Snapshot Isolation (section 4.2)
真打登場です(ぼくにとっての)。
Snapshot Isolation (SI) は multi-version (MV) の方法であるため、履歴の記述方法を拡張しなくてはなりません。具体的には、データアイテムに対してバージョン番号を付与することで可能になります。 Section 3 で出てきた履歴 H1 (これは良く見る、口座間のお金の受け渡しをモデル化しています。途中で T2 が 100 となるべき合計を 10 + 50 = 60 と見てしまっています)
H1: r1[x=50] w1[x=10] r2[x=10] r2[y=50] c2 r1[y=50] w1[y=90] c1
を SI で書き換えてみると次のようになります。
H1.SI: r1[x0=50] w1[x1=10] r2[x0=10] r2[y0=50] c2 r1[y0=50] w1[y1=90] c1
H1.SI が serializable execution のデータフローを持っています。MV の履歴は single value (SV) の履歴に常にマップすることが出来るそうです(c.f. [BHG] chapter 5)。
まずは、 Snapshot Isolation が Serializable ではないこと。
H5: r1[x=50] r1[y=50] r2[x=50] r2[y=50] w1[=-40] w2[y=-40] c1 c2
直列にすると、1 と 2 のどちらを先にもってきても、 x, y どちらかが -40 になり、 50 という値は読めないので、 Serializable ではない履歴になります。一方で、書き込みは被っていないので、バージョンは自明で Snapshot Isolation の場合は可能な履歴です。この履歴では、データベース全体に渡る制約(Constraint)を模倣しています。具体的には、
x + y > 0
という制約があると考えると、各トランザクションでは満たされているものの、T1, T2 が終わった段階で破れてしまっています。
論文では、この履歴から、 Read Skew / Write Skew という 2 つのアノマリー(anomaly)を抽出して、順序を導きます。
A5A: r1[x] ... w2[x] ... w2[y] ... c2 ... r1[y] ... (c1 or a1) / Anomaly: Read Skew A5B: r1[x] ... r2[y] ... w1[y] ... w2[x] ... (c1 or c1) / Anomaly: Write Skew
2 つのデータ x, y に関連した制約があると心で思って見ると、Read Skew では、T1 は別のトランザクションが書き換える前後で関連データを読んでしまっている、と読めます。 Write Skew は、2 つのトランザクホンで読むデータアイテムと書くデータアイテムが互い違いになっています。
Read Skew に注目すると、 READ COMMITTED では許可されます。Snapshot Isolation では、 r1[y] が multi-version で w2[y] の前の情報を見るため、禁止される(single value に変換したときに、 A5A に落ちるものは無い、と解釈する)ことが分かります。
READ COMMITTED << Snapshot Isolation
次に、REPEATBE READ と Snapshot Isolation の順序を考えてみます。
REPEATABLE READ における Write Skew の可能性を考えてみると、 x は T1 に読まれた後、 T2 が書かれるので、 "data-item" の read lock に long duration を要求する REPEATABLE READ では禁止されることが分かります。注目している Snapshot Isolation では、 write が被っていないので許可されています。
ところが、次の 3つのアノマリー(P は predicate)
A1: w1[x] ... r2[x] ... ((c1 or a1) and (c2 or a2)) / Anomaly: Dirty Read A2: r1[x] ... w2[x] ... c2 ... r1[x] ... c1 / Anomaly: Fuzzy Read A3: r1[P] ... w2[y in P] ... c2 ... r1[P] ... c1 / Anomaly: Phantom
のうち、 A3 は、 "predicate" の read lock に short duration しか要求しない REPEATABLE READ では許可され、 Snapshot Isolation では禁止されます。よって 2 つの間の順序は incomparable となります。
REPEATABLE READ >><< Snapshot Isolation
「A1 - A3 のアノマリーを禁止する」という隔離レベルを ANOMALY SERIALIZABLE と定義すると、それは anomaly の観点から定義した "ANSI の SERIALIZABLE" 相当のレベルとなります(当然ですが、 mathematically SERIALIZABLE ではありません)。
ANOMALY SERIALIZABLE << SNAPSHOT ISOLATION
Other Multi-Version Systems (section 4.3)
Oracle の Consistent Read (SQL ステートメントが開始された時点から見て、直近のデータを読む)が紹介されています。
READ COMMITTED << Oracle Consistent Read << REPEATABLE READ
Summary and Conclusions (section 5)
論文中で紹介された分離レベルが、ひとつの図にきっちりとまとめられています。
まとめ(section 5 summary) にある分離レベルとその関係図。
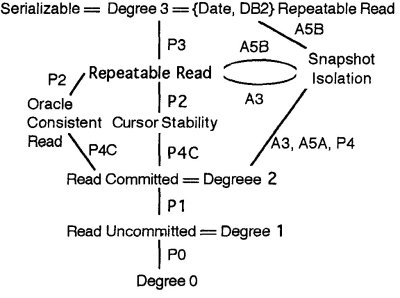
Read Committed より上で、 Serializable までは行かないというあたりで、機能と性能がぶつかりあうのかなぁ、と感じられます。具体的には、 "long duration な read predicate lock" が重たいはずなので、そこを回避しつつかなり高い隔離レベルを実現する Snapshot Isolation は興味深いものです。
以上、(ぼくの興味である) Snapshot Isolation を中心に、論文を読んでみたメモでした。
補足
Multiversion concurrency control (MVCC) については、次の論文に詳しく(まとめ的に)記述してあります。
Concurrency control algorithms for multiversion database systems
Concurrency control algorithms for multiversion database systems
authors:
Philip A. Bernstein, Nathan Goodman
オリジナルなアイデアはこちらの論文です。
author: D.P. Reed
Naming and Synchronization in a Decentralized Computer System
"Naming and Synchronization in a Decentralized Computer System". MIT dissertation. http://www.lcs.mit.edu/publications/specpub.php?id=773. Retrieved September 21 1978.